
{kind=link}
Data Mining and Fashion Trend Forecasting
The realm of fashion trend forecasting has long remained enigmatic, drawing the attention of major brands willing to invest substantial sums in consulting firms for glimpses into the future. This pursuit straddles the line between art and science, encompassing a spectrum of expertise—from entities like K-HOLE, which emerged as an art collective critiquing corporate culture before delving into trend forecasting, to academic researchers at Cornell University, leveraging social media data to delve into the anthropology of fashion on a global scale.
In contemporary times, social media platforms serve as rich repositories of aggregated information, presenting a veritable goldmine for data analysis. This reservoir of data holds the key to unlocking the scientific aspect of trend forecasting, particularly in deciphering and predicting the cultural undercurrents propelling the fashion industry forward.
Traditional Trend Forecasting Approaches
In the realm of trend forecasting, traditional methods such as analyzing sales data and trend reports have long been the go-to for brands seeking insights into consumer desires and behaviors. However, in today's digital era characterized by personalized experiences and social media influence, consumer preferences are evolving rapidly, reshaping purchasing patterns. Rather than emanating from a select few influencers, trends now percolate from the cultural zeitgeist, posing a challenge for marketers and designers striving to keep pace with ever-changing consumer whims.
Within the fashion industry, the journey of trend adoption often commences with trend-forecasting agencies like F-trend based in India. These agencies serve as the starting point for seasonal design processes, disseminating forecasted trends to myriad designers across the industry. Notably, color trends wield significant influence, permeating through textile design and manufacturing processes, thereby shaping the supply chain dynamics.
Simultaneously, consumers are actively engaging with these trends on social media platforms such as Twitter, Instagram, and Facebook, offering real-time feedback and expressing preferences. It's not uncommon for consumers to voice their discontent or boredom with colors or styles that designers have earmarked as dominant in upcoming palettes, underscoring the need for agility and responsiveness in the fashion ecosystem.
Application programming interfaces- APIs
Accessing the necessary data involves tapping into the offerings of various social media platforms, most of which provide public Application Programming Interfaces (APIs). APIs, as briefly introduced in Chapter 2 in the context of natural language processing, serve as the foundational components of software programs, facilitating communication between applications.
In a typical software web architecture, there's a need to segregate the front-end interface—where users interact visually via a browser—from the back-end database and applications housing the business logic.
Bridging these distinct realms requires the establishment of an API, acting as a conduit between them. This API comprises multiple endpoints tailored to enable interaction between front-end user-interface elements and the data stored in the back-end database. Visualizing such a system often resembles the structure depicted in Figure below.
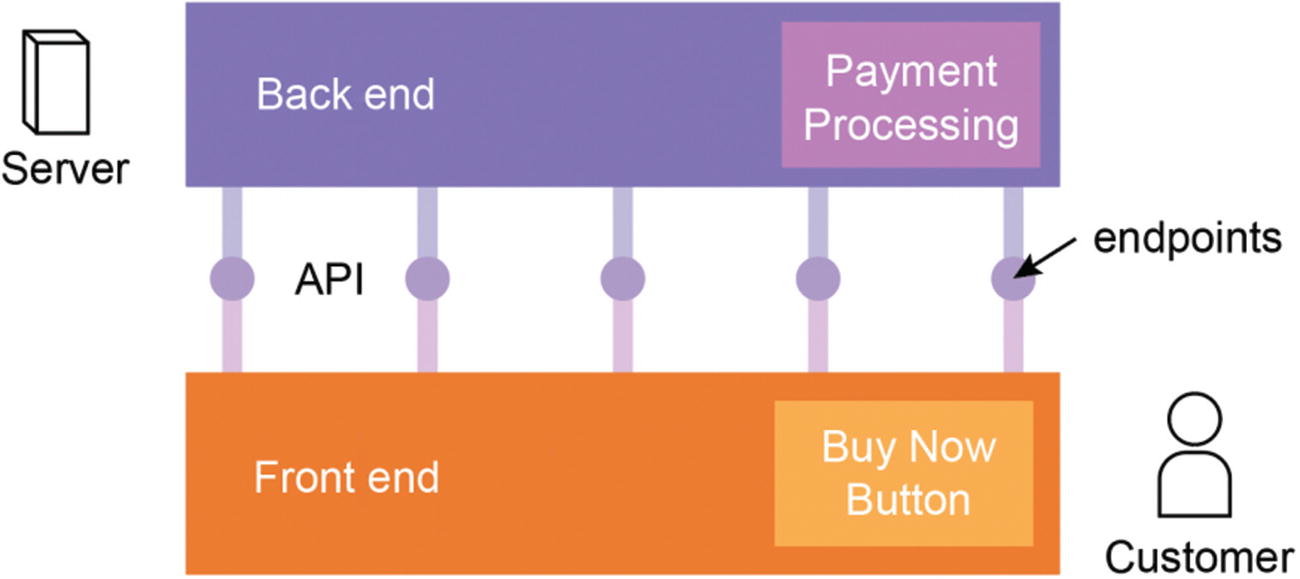
A simplified diagram of a generic web application architecture
Your customer sees the front-end interface hosted on a web site. They can do things like click the Buy Now button, for example, which would trigger payment-processing scripts in the back end.
Your back end might talk to other companies’ APIs that are related to the services you use. For example, Stripe is a common payment-processing service. In Figure 9-1, the payment processing app in the back end would connect with Stripe’s API to carry out the task required. This is appealing because by revealing these endpoints, you can give access to programs running on your back end, allowing other services and platforms to be built on top of your API.
APIs can also do things like provide access to a database of content, like tweets. In the example of social media, companies such as Twitter have APIs where you can access tweet data in a form that’s easy to collect and analyze programmatically. That means for a given topic or hashtag, you can go through public tweets, and using NLP techniques, analyze the general sentiment around a marketing campaign without ever having a human read a single tweet. There are, in fact, many examples of scripts people have written to do exactly this available online.
Data Web Scraping
For some applications, web scraping might provide an alternative for sites that don’t provide a public API or for platforms that have limitations in their API.
Web scraping is a method of extracting large amounts of data from a website programmatically, without using an API. The data can vary in format and subject and include words, tables, hashtags, numbers, comments, images, and more.
Web scraping is often an essential component in creating large datasets that can be further analyzed using machine learning and other artificial intelligence techniques. Web scraping is typically less reliable and more difficult to implement than programmatic access over an API.
Web scrapers depend on the structure of the website staying the same. If the site changes even in a small way, that change might break the scraper.
As a disclaimer, many companies do not allow you to scrape their websites without their consent. Unmindfully scraping can also lead to site-reliability issues: if you try to get too much data at once, you might break the web site for other users. Scraping can get you into legal trouble if a company’s Terms of Service forbids it. You might consider consulting a lawyer if you’re planning ambitious web scraping projects.
Web Crawlers
Web crawlers, or site crawlers (mentioned in Chapter 2), provide an automated method of extracting information from web sites in a systematic way. In the event that your project requires data that will be updated daily, a web crawler might be the most effective means of collecting this data.
Web crawlers are an essential tool on the Internet. Google and other search engines use web crawlers to give constantly updated information on their search pages. You’ll often hear people refer to web crawlers as a spider, because they “crawl” through the Web and examine sites.
The way data mining and web crawlers work together is that web crawlers can be used as a first step in data mining, to collect the raw data that is desired.
Data Warehousing
Where does all this data get stored after it’s collected? The answer is most likely that it’s being stored in a data warehouse. A data warehouse is a software-based central place where a company’s data is stored. It can contain one or more databases and is designed to store large amounts of data.
Data warehouses are optimized for reporting and analysis. The hardware that the data warehouse lives on is called a server. Servers are computers designed to store data and process requests. These servers are usually housed in a server farm, also called a data center
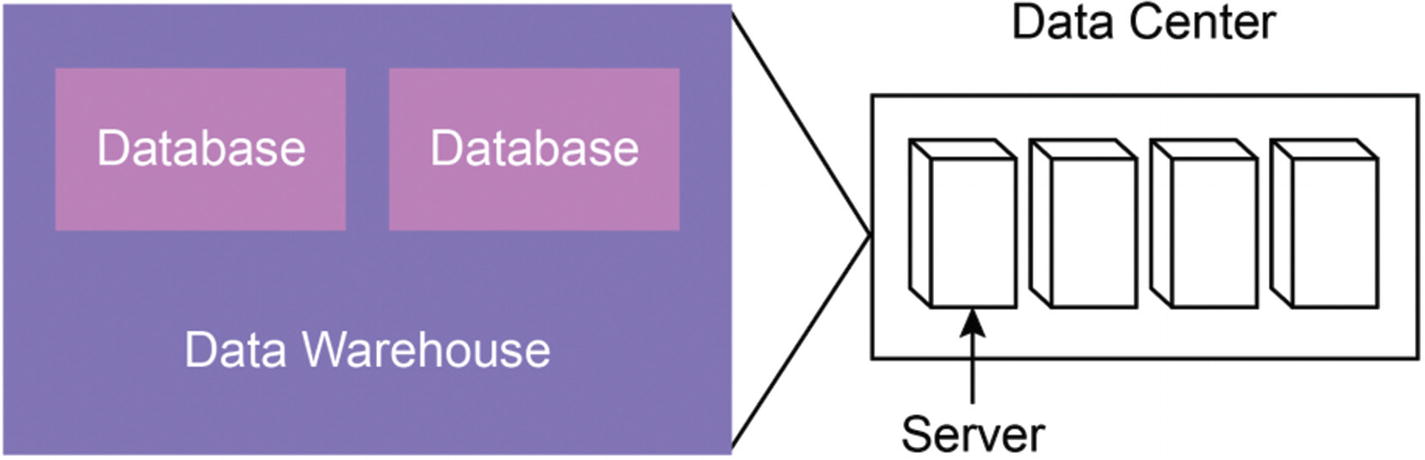
Relationships between a database, data warehouse, server, and data center (or server farm). On the left are the components that exist as software components. On the right is the physical hardware that holds those software components.
For quick projects and experimentation, you do not need to set up a data warehouse. Data warehouses are an optimization used when you’re looking to scale solutions that have already been proven to work. For production, data will be fed through a data pipeline. A data pipeline is a series of programs that transform data from one state to another.
In this example, the process transforms raw data into data that analysts can use to create trend reports. The data starts at websites, third-party sites, and APIs, and then is moved to the server or program to be processed. From there, it is stored in a data warehouse, where analysts can access it to create trend reports. This process can be seen in the Figure below.
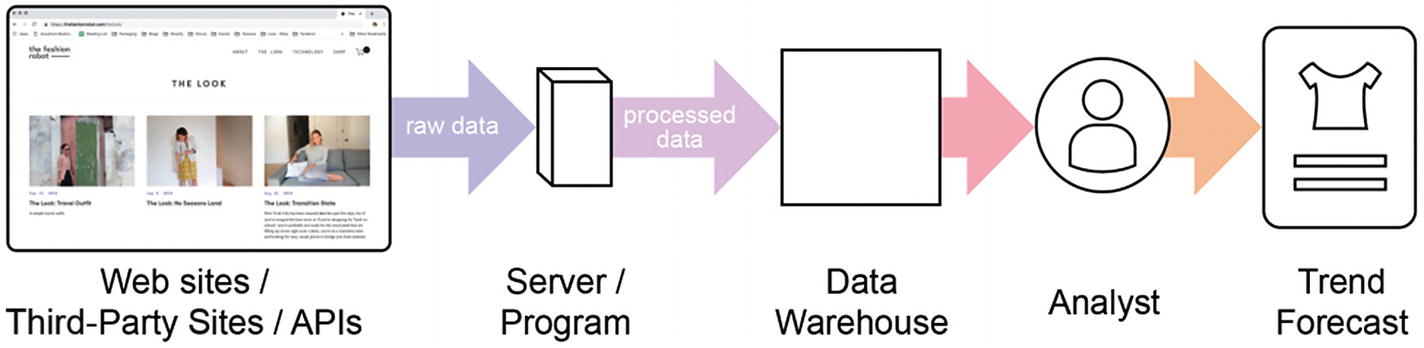
A simplification of a data pipeline
Q&A Section
Q1: What are the primary challenges associated with traditional trend forecasting methods in the fashion industry?
A: Traditional trend forecasting methods, such as analyzing sales data and trend reports, face challenges in keeping pace with rapidly evolving consumer preferences driven by social media influence and personalized experiences.
Q2: How do trend-forecasting agencies contribute to the fashion ecosystem?
A: Trend-forecasting agencies like F-trend serve as catalysts for seasonal design processes, disseminating forecasted trends to designers and influencing supply chain dynamics, particularly in the realm of color trends.
Q3: What role do APIs play in accessing real-time data for trend forecasting?
A: APIs serve as conduits for accessing real-time data from social media platforms, providing invaluable insights into consumer sentiments and preferences, thereby enabling brands to adapt swiftly to emerging trends.
Meta Description: Explore the dynamic intersection of data mining and fashion trend forecasting, from traditional methodologies to modern approaches leveraging APIs and web scraping. Uncover how trend-forecasting agencies and web crawlers contribute to the ever-evolving fashion ecosystem.